
I recently wrote about how to properly understand scientific studies. In this post, I want to discuss three recent pieces of news that might be producing science cynicism. I’ll present each item, give examples of how it might be simplistically misconstrued, and then explain its true significance.
The replication crisis
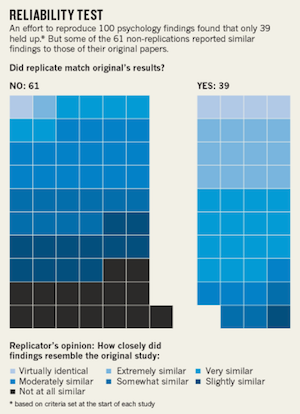
In 2015, The Center for Open Science organized an effort to reproduce 100 published psychology experiments. In 61 cases, they were unable to reproduce the results of the original experiment. And there seems to be a similar problem in the other branches of science.
The simplistic takes:
- What those earlier studies were supposed to have proven was proved wrong after all!
- Some of those initial researchers must have been faking their results (or they must have made bad mistakes) but now they’ve been caught!
- If studies can come out one way one time and the opposite way the next time, they are worthless as a way of finding the truth!
The real story:
- Single studies were never supposed to be able to prove anything in the first place.
- Researchers who cited those past single studies as if they were authoritative were wrong to do so.
- Attempting to replicate past studies is a key part of the scientific process, but we currently don’t devote enough of our resources to doing that.
- Scientists aren’t sufficiently incentivized to spend time replicating the work of others. It’s more flashy to break new ground than to repeat old experiments. (And it saves time when you can just cite a single past study as the background for your new work, rather than waiting until enough data is collected to firmly establish that background in the first place.)
- The real purpose of the Open Science effort was not to disprove those initial studies, or to claim there is a fundamental flaw in science, but to emphasize how important it was to have been doing the work of replication all along.
The lesson:
Replication is a normal and essential part of the scientific process, and one that we need to be doing more.
P-hacking
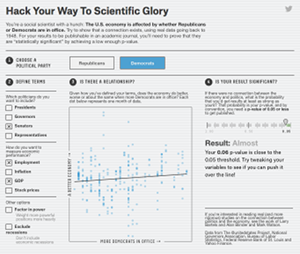
This was not so much a recent event as a loophole that existed for a long time in the process scientists had developed over the years for gaining knowledge through studies and experiments. What happened recently was a very clever demonstration of the loophole by FiveThirtyEight.com, and discussion about how to patch it.
Basically, the loophole is/was this: If you gather enough data about anything, it’s possible to find all kinds of connections between things, many of which will make no sense at all. In the case of the FiveThirtyEight “study,” correlations were found between eating cabbage and having an “innie” belly button, and between salt intake and satisfaction with your Internet provider. FiveThirtyEight.com also created an interactive web app that let readers p-hack their way to a desired conclusion about the economic success of the two major political parties.
The simplistic takes:
- Science (or math, or statistics) can be used to prove anything!
- Any real conclusion accepted by scientific consensus is potentially just as unreal as the correlation between cabbage and innies.
The real story:
- In real science, single studies can’t prove anything.
- In real science, what eventually proves a thing is probability: if it beats the odds again and again. The first study that shows some effect merely suggests that there’s a good chance it might be a real effect. The first time that study is replicated, it becomes much more likely the effect is real, and less likely that it was due to randomness or human error or bias, etc. If the results continue to be replicated, the odds that the effect is real get better and better until, at a certain point, the scientific community accepts it as proven.
- Therefore, p-hacking is really more a time waster than a fatal flaw in science. A result we get by p-hacking might well be real, but shouldn’t be counted in the above calculation of probabilities, because it hasn’t really beaten any odds. We rolled the dice first, and then announced what numbers we were trying to hit.
- The fix to the problem of p-hacking is simple, though it might not be easy to implement. We simply require scientists to announce what effect they’re looking for before they begin their experiment. If they then get that result, it still won’t prove the effect is real, but at least we can include it in our calculation of the odds moving forward.
- Some scientific journals are also talking about putting less weight on p-values alone to determine whether a paper is fit for publication, instead making a more holistic judgement on a paper’s soundness based on all its characteristics.
The lesson:
We’re continuing to find potential loopholes in the scientific process, but as we find them, we fix them. A process that was already very good at finding truths about the universe is only getting better.
Cancer causes
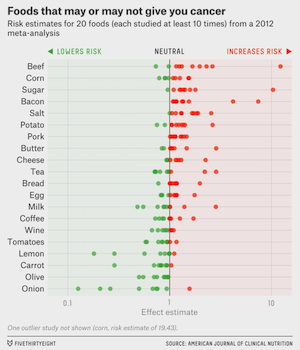
In 2013, researchers John Ioannidis and Jonathan Schoenfeld picked common ingredients from a cookbook and tried to find existing studies linking those foods with cancer. Of 50 foods with at least ten studies conducted for them, 40 had at least one study linking them to cancer.
The simplistic takes:
- Almost anything can be “proven” to cause cancer!
- Almost everything causes cancer!
The real story:
- Individual studies can’t prove anything, but a number of studies will probably cluster around the true answer.
- The data collected by the researchers does just that. It’s not at all the case that it’s all over the map. Instead, for each food, there’s a definite sense that the results are pointing in one direction or the other.
- Just because you can find a single study that sits on the opposite side of the center line from the rest, doesn’t mean it contradicts the rest, especially when, on the whole, they are all clustering pretty reasonably around a given point.
- Even if effect for some foods is on the positive side of the chart, it’s still very small for many of them. Many people confuse “proven” with “big”. Many effects that are proven are so small, they should make very little practical difference in our lives. (For more on this, read my post about “confirmation exaggeration.”)
- Ioannidis does point out that the range of results is wider than they should be, but I believe he’s speaking purely mathematically, only accounting for randomness and not for minor human error or variations in the design of the studies. What he’s really essentially saying is that we need to be more careful about designing and conducting the actual experiments so that the only thing we’ll have to deal with is randomness and not human factors on top of that. Even though the scientific process as a whole was designed to handle human error, that’s no excuse to get sloppy and put more strain on the process than necessary. The better designed and executed our experiments are, the fewer of them we’ll need to home in on the final answers.
The lesson:
Accurate results are always going to cluster around the real answer, so we shouldn’t take data points at the extremes of the cluster as contradictions of the overall conclusion. However, we should certainly be doing all that we can to keep the clusters as tight as possible.